Agent-based models of language change
In my PhD project (start: 2019), I study the social, cognitive and language-specific factors that drive language change using agent-based models. I apply my models to real-world case studies, in which questions about morphology and language contact are common denominators:
(links to recent publications per topic)
- Contact-induced morphological simplification. Agent-based model of Alorese, Eastern Indonesia.
- Conversational priming in repetitional responses. Agent-based model inspired by Lithuanian dialects.
- Learning of inflection classes. Cognitively inspired neural network (Adaptive Resonance Theory) applied to Romance languages.
My research is supported by an FWO PhD Fellowship Identifying drivers of language change using neural agent-based models. I was previously funded by the AI Flanders program.

Computational historical linguistics
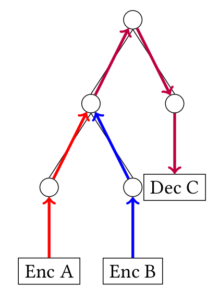
In my MSc thesis (supervisors: Gerhard Jäger and Jelle Zuidema), and a subsequent journal article, I applied the machine learning paradigm to reconstruct language ancestry. I proposed the task of word prediction: by training a machine learning model on pairs of words in two languages, it learns sound correspondences between the two languages and should be able to predict unseen words. I used two neural network models, an encoder-decoder and a structured perceptron. By performing the task of word prediction, results for multiple tasks in historical linguistics can be obtained, such as phylogenetic tree reconstruction, identification of sound correspondences and cognate detection.
- Journal of Language Modelling Paper Word prediction in computational historical linguistics
- MSc thesis
- Interactive notebook on Github, thesis source code on Bitbucket
- Blog post on ILLC CLC lab web page
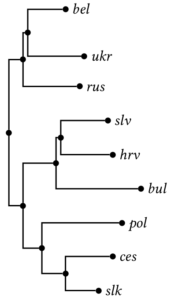
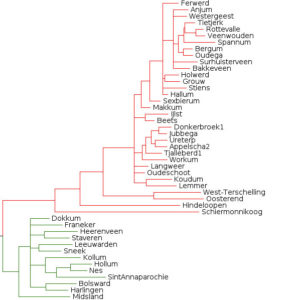
In my BSc thesis (supervisors: Alexis Dimitriadis and Martin Everaert) [pdf], I used bayesian inference to create a kinship tree of Dutch dialects, using data from the Reeks Nederlandse Dialectatlassen. The words were aligned and converted to phonetic features, in order to be processed by a bayesian inference algorithm.
Other projects: Linguistic data collection and processing
Crowdsourcing, asking lay people to perform a task, can be a powerful tool to collect data on language use. At the Dutch Language Institute (INT), I developed the platform Taalradar (language radar) to ask speakers about their attitude towards neologisms, chart Dutch language variation and filter a corpus for language learning purposes.
Furthermore, I was involved in tools to process linguistic data. I developed deep neural models for linguistic enrichment of historical text. I developed the web interface for DiaMaNT, a diachronic semantic lexicon of the Dutch language. I was involved in the software development of CLARIAH Chaining Search, a Python library and Jupyter notebook that facilitates combined search in lexica, corpora and treebanks. I contributed to TREC OpenSearch, a platform developed to evaluate academic search engine algorithms on real users.